On April 14, the SNIA Compute Memory and Storage Initiative (CMSI) held a webcast asking the question – Do You Wanna Program Persistent Memory? We had some answers in the affirmative – answering the call of the NVDIMM Programming Challenge.
The Challenge utilizes a set of systems SNIA provides for the development of applications that take advantage of persistent memory. These systems support persistent memory types that can utilize the SNIA Persistent Memory Programming Model, and that are also supported by the Persistent Memory Development Kit (PMDK) Libraries.
The NVDIMM Programming Challenge seeks innovative applications and tools that showcase the features persistent memory will enable. Submissions are judged by a panel of SNIA leaders and individual contest sponsors. Judging is scheduled at the convenience of the submitter and judges, and done via conference call. The program or results should be able to be visually demonstrated using remote access to a PM-enabled server.
NVDIMM Programming Challenge participant Steve
Heller from Chrysalis Software joined the webcast to discuss the Three Misses
Hash Table, which uses persistent memory to store large amounts of data that
greatly increases the speed of data access for programs that use it. During the webcast a small number of
questions came up that this blog answers, and we’ve also provided answers to subjects
stimulated by our conversation.
Q: What are the rules/conditions to access SNIA PM hardware
test system to get hands on experience? What kind of PM hardware is there?
Windows/Linux?
A: Persistent memory, such as
NVDIMM or Intel Optane memory, enables many new capabilities in server
systems. The speed of storage in the
memory tier is one example, as is the ability to hold and recover data over
system or application resets. The
programming challenge is seeking innovative applications and tools that
showcase the features persistent memory will enable.
The specific systems for the
different challenges will vary depending on the focus. The current system is built using
NVDIMM-N. Users are given their own
Linux container with simple examples in a web-based interface. The users can also work directly in the Linux
shell if they are comfortable with it.
Q: During the
presentation there was a discussion on why it was important to look for “corner
cases” when developing programs using Persistent Memory instead of regular
storage. Would you elaborate on this?
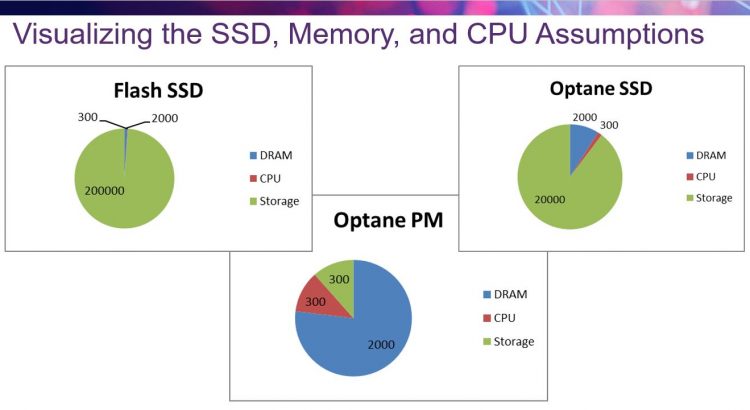
A: As you can see in the chart at the top of the blog post, persistent memory significantly reduces the amount of time to access a piece of data in stored memory. As such, the amount of time that the program normally takes to process the data becomes much more important. Programs that are used to data retrieval taking a significant amount of time can then occasionally absorb a “processing” performance hit that an extended data sort might imply. Simply porting a file system access to persistent memory could result in strange performance bottlenecks, and potentially introduce race conditions or strange bugs in the software. The rewards of fixing these issues will be significant performance, as demonstrated in the webcast.
Q: Can
you please comment on the scalability of your HashMap implementation, both on a
single socket and across multiple sockets?
The implementation is single threaded. Multiple threading
poses lots of overhead and opportunity for mistakes. It is easy to saturate
performance that only persistent memory can provide. There is likely no benefit
to the hash table in going multi-threaded. It is not impossible – one could do
an example of a hash table per volume. I have run across multiple sockets that
were slower with an 8% to 10% variation in performance in an earlier
version. There are potential cache
pollution issues with going multi-threaded as well.
The existing implementation will scale one to 15 billion
records, and we would see the same thing if we have enough storage. The
implementation does not use much RAM if it does not cache the index. It only uses 100mb of RAM for test data and
does not use memory.
Q: How would you compare
your approach to having smarter compilers that are address aware of
“preferred” addresses to exploit faster memories?
The Three Misses implementation invented three new storage
management algorithms. I don’t believe
that compilers can invent new storage algorithms. Compilers are much improved since their
beginnings 50+ years ago when you could not mix integers and floating-point
numbers, but they cannot figure out how to minimize accesses. Smart compilers will probably not help solve this
specific problem.
The SNIA CMSI is continuing its efforts on persistent memory
programming. If you’re interested in
learning more about persistent memory programming, you can contact us at pmhackathon@snia.org to get
updates on existing contests or programming workshops. Additionally, SNIA would be willing to work
with you to host physical or virtual programming workshops.
Please view the webcast and contact us with any questions.